SNS、SQSと続けてAWSの非同期系サービスを体感してきましたが、次はAWS Lambdaに手を出してみました。
「名前は聞いたことあるけど、結局Lambdaって何ができるの?」「常駐で動いている普通のサーバーとどう違うの?」というあたり、自分も最初はかなりふわっとした状態でした。
この記事では、Lambdaを「ちょこっと動くプログラム」として身近な例えで腹落ちさせる概念パートと、AWSコンソールで最小構成の関数を作って実際に動かしてみるパートを、自分が触りながら腹落ちさせていった流れそのままに書き残していきます。
最後にはSQS連携で意外とハマりやすい落とし穴にも触れるので、これからLambdaを触る人やSQSと組み合わせて使いたい人の参考になれば嬉しいです。
記事の目次
- AWS Lambdaって結局なに?「ちょこっと動く」を自販機に例えて理解する
- Lambdaを構成する3つの登場人物|コード・ランタイム・イベント
- イベントの正体は「外から飛んでくるJSON」|自分からは動かない仕組み
- 常駐型サーバーとの本質的な違いは「プロセスの寿命」
- 実践前に押さえておこう|実行ロール・CloudWatch Logs・ウォームスタート
- AWSコンソールでLambda関数を作成してみる
- テストイベントを作成して実行する|Duration・Init Durationの読み方
- CloudWatch Logsで実行ログを確認する|printを足してみる
- 実運用ではreturnの行き先がモデルで変わる|同期・非同期・ポーリング
- SQS連携の落とし穴|try/exceptの握りつぶしが「成功」と判定される
- Lambdaを腹落ちさせるために押さえた3つのポイントと、次に試したいこと
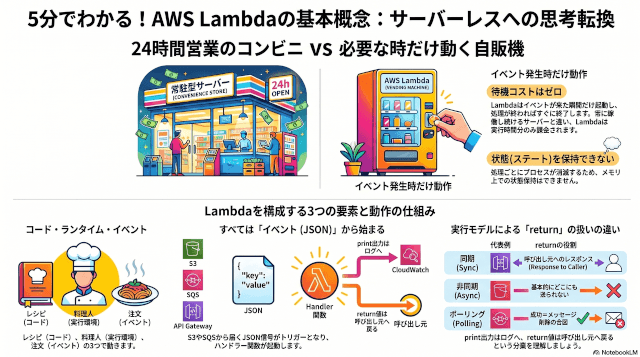
AWS Lambdaって結局なに?「ちょこっと動く」を自販機に例えて理解する
AWS Lambda(ラムダ)はひとことで言うと、「何かが起きた瞬間だけ、ちょこっとプログラムを動かしてくれる」サービスです。
イメージとしては自販機が近いと自分は思っています。
普段は静かに置いてあるだけで、お金が入った瞬間だけ中身が動いてジュースを出してくれる。
Lambdaも、何かのきっかけ(イベント)が来た瞬間だけ起動して、処理が終わったらサッと閉じるという動きをします。
これが意外と直感に反するところで、サーバープログラムを書いてきた人ほど最初は「で、いつ動いてるの?」と戸惑います。
普通のサーバーは24時間営業のコンビニみたいに常にスタッフが待機していて、お客さんが来てもすぐ対応できる状態を維持しています。
一方Lambdaは必要な時だけパッと開店して、用が済んだらすぐ閉店する店みたいな動き方で、待機時間にはそもそもプロセスすら存在していません。
| 普通のサーバー | Lambda | |
| 動作モデル | 常駐して待機 | イベントごとに起動・終了 |
| イメージ | 24時間営業のコンビニ | 必要な時だけ開く店 |
| 起動コスト | 立ち上げっぱなしの料金 | 動いた時間ぶんだけ |
「動かない時間にはお金がかからない」というのが、最初に押さえておきたいLambdaの大きな魅力です。
Lambdaを構成する3つの登場人物|コード・ランタイム・イベント
Lambdaの動きを分解すると、登場人物は3つだけです。
コード・ランタイム・イベント。
これさえ押さえれば、Lambdaの基本構造はほぼ理解できます。
| 登場人物 | 誰が用意するか | 役割 |
| コード(ハンドラー関数) | 自分 | 実際にやりたい処理 |
| ランタイム | AWS | コードを動かす実行環境 |
| イベント | 別の仕組み | コードを動かすきっかけ |
ランタイムは、料理人みたいなものだと思うとしっくりきます。
自分はレシピ(コード)を渡すだけで、それを実際に読んで料理してくれるのがランタイム。
Pythonで書いたレシピならPythonランタイム、Node.jsで書いたレシピならNode.jsランタイム、というように「読める料理人」の種類だけランタイムが用意されています。
ややこしいのが、Lambdaに登録するコードは普通のサーバーと違って特定の関数だけを書く点です。
これをハンドラー関数と呼びます。
「お客さんが来たら最初に対応する人」みたいな立ち位置で、お客対応・注文受付・配膳といった裏方の処理はすべてAWS側がやってくれます。
自分が書くのは、「具体的に何をするか」のレシピ部分だけです。
def lambda_handler(event, context):
# ここに処理を書く
return {"statusCode": 200, "body": "Hello from Lambda!"}
このシンプルさがLambdaの気持ちよさで、`event`の中身がどう届くか、戻り値をどう呼び出し元に返すか、といった面倒な部分は気にしなくてOKです。
イベントの正体は「外から飛んでくるJSON」|自分からは動かない仕組み
3つの登場人物のうち、概念がいちばんふわっとしているのがイベントです。
ここを掴むかどうかでLambdaの動きが見えるか決まります。
イベントは、ひとことで言うと「Lambda関数を動かしてください、と外から飛んでくる信号」です。
自販機の話に戻すと、お金が入った瞬間にだけ自販機が動き出すのと同じで、Lambdaも何かのイベントが届いて初めて起動します。
Lambdaは自分から能動的に動くことはなく、必ず誰か(何か)からのイベントで動かされる側です。
イベントを送ってくる仕組みのことをイベントソースと呼び、AWSのいろんなサービスがLambdaのトリガーになってくれます。
| イベントソース | 主な使われ方 |
| API Gateway | HTTPリクエストを受けてLambdaを呼ぶ |
| S3 | ファイルがアップロードされたら起動 |
| SQS | キューにメッセージが入ったら起動 |
| SNS | トピックに通知が来たら起動 |
| EventBridge | 定時実行や特定イベントで起動 |
| DynamoDB Streams | テーブルの変更を起点に起動 |
そして、これらのイベントはすべてJSONとしてLambdaに渡されます。
実際に届くイベントの中身を覗くと、たとえばS3イベントならこんな感じです。
{
"Records": [
{
"eventSource": "aws:s3",
"s3": {
"bucket": {"name": "my-bucket"},
"object": {"key": "uploaded-file.png"}
}
}
]
}
ハンドラー関数の第1引数 `event` にこのJSONがそのまま入ってくるので、自分のコードはこの中身を見て、必要な処理を書くだけです。
ここで一つ大事なポイントが、「Lambdaに常駐してデータを取りに行く」という発想は持ち込まないことです。
たとえば「定期的にDBの状態を見に行きたい」みたいな処理を書きたくなったとき、Lambda側でループを回すのではなく、EventBridgeに「1分おきにLambdaを呼んで」と頼むのが正解になります。
イベント駆動という言葉だけだと固く感じますが、要は「Lambdaは呼ばれて初めて動く受け身の関数」だと思っておくとイメージしやすいです。
常駐型サーバーとの本質的な違いは「プロセスの寿命」
「Lambdaはイベントが来た瞬間だけ動く」と聞くと、サーバープログラム経験者ほど「いや、普通のWebサーバーもリクエストが来た瞬間しか動かないし、cronも時間が来たら起動するだけだよね?」と思うかもしれません。
自分も実際そう感じました。
ここで言葉を整理しておくと、Lambdaと常駐型サーバーの本質的な違いはイベント駆動かどうかではなく、プロセスが生きている時間です。
| 普通のサーバー | Lambda | |
| プロセス | 常駐し続ける | リクエストごとに起動・終了 |
| 状態の持ち方 | プロセス内のメモリで保持できる | リクエスト間で持ち越せない |
| 例えるなら | コンビニの店員 | 出張シェフ |
普通のサーバーは、リクエストが来ようが来まいがプロセスは生き続けています。
リクエストを受けるたびに同じプロセスがハンドラーを実行し、レスポンスを返したらまた次のリクエストを待つ。
一方Lambdaは、イベントごとにプロセスごと起動して、処理が終わったらプロセスごと終了する動きです。
これは普段サーバーを書いてきた人ほど引っかかります。
具体的には、こんなコードがLambdaでは思った通りに動きません。
- グローバル変数で状態を持つ:次の呼び出しまで残っている保証がない
- DBコネクションプールを使い回す:プロセスが死ぬのでプールも消える
- バックグラウンドスレッドで非同期処理:ハンドラーが終わるとスレッドも止まる
cronで起動するシェルスクリプトは、毎回プロセスを立ち上げて終わったら閉じるという意味で、実はLambdaにかなり近い動きです。
「cronで動くスクリプトをコード単位で書く」くらいのイメージで捉えると、Lambdaの動きと噛み合いやすいと思います。
実践前に押さえておこう|実行ロール・CloudWatch Logs・ウォームスタート
実際にコンソールを触る前に、Lambdaを実運用で使うときに必ず出てくる前提知識を整理しておきます。
ここを飛ばすと「あれ?権限が…」「ログが見つからない…」と詰まりやすいので、概念だけサクッと押さえておきましょう。
実行ロール|Lambda関数自身の権限の話
Lambdaには実行ロールというIAMロールを必ず1つ紐付けます。
これが地味に紛らわしくて、「Lambdaを呼び出す側の権限」ではなく「Lambda関数自身がAWSのリソースに触るときの権限」を指します。
たとえばLambdaの中からS3にファイルを書きたいなら、実行ロールにS3への書き込み権限を付ける必要があります。
最低限の動作には `AWSLambdaBasicExecutionRole` というマネージドポリシーが付いていればOKで、これだけでCloudWatch Logsへの書き込み権限が手に入ります。
CloudWatch Logs|printの出力先になる場所
Lambda関数の中で `print()` や `console.log()` を書いたとき、その出力はCloudWatch Logsという場所に集約されます。
普通のサーバーなら標準出力をターミナルで見ればよかったところが、LambdaではコンソールでもサーバーでもなくCloudWatch Logsを見に行くことになります。
「ログはCloudWatch Logsを見る」と覚えておくと、後の動作確認で迷わずに済みます。
コールドスタートとウォームスタート|「毎回プロセスが死ぬ」の例外
先ほど「Lambdaは毎回プロセスが起動・終了する」と書きましたが、これは厳密にはちょっと雑な説明で、実際にはAWS側で実行環境を一定時間使い回す仕組みになっています。
- コールドスタート:新しい実行環境を立ち上げて起動する。初回は数百msかかる
- ウォームスタート:直前の実行環境がまだ生きているので、即座に再利用される
この性質を逆手に取ると、ハンドラー関数の外側に初期化コードを置くと、ウォームスタート時はそれを使い回せます。
DBクライアントの生成や設定の読み込みなど、起動コストが高い処理はハンドラー外に出しておくと有利です。
# ハンドラーの外(コールドスタート時のみ実行)
db_client = create_db_client()
def lambda_handler(event, context):
# ハンドラーの中(毎回実行される)
return db_client.fetch(...)
ただしウォームが続く保証はないので、状態管理(カウンタなど)をここに置くのはNGです。
あくまで「あれば嬉しい最適化」として捉えるのが安全です。
DB認証情報の置き場所|コードに直書きはNG
Lambdaから外部DBに接続したくなったとき、認証情報をコードに直書きするのは絶対に避けたいところです。
AWSが用意している置き場所として、主に3つの選択肢があります。
| 置き場所 | 特徴 |
| 環境変数 | 一番手軽。設定タブから登録できる |
| Parameter Store | 階層構造で管理できて無料枠あり |
| Secrets Manager | 自動ローテーション対応で本格運用向け |
最初は環境変数で十分ですが、本番のDBパスワードのように厳格に管理したい情報はSecrets Managerに置くのが鉄板の使い分けです。
ハンドラー関数とLambda関数の用語の境界
最後に紛らわしい用語の話を一つ。
「Lambda関数」と「ハンドラー関数」は別物です。
- Lambda関数:AWSに登録する単位全体(コード+設定+メタデータ)
- ハンドラー関数:Lambda関数の中で、エントリポイントとして指定される1つの関数
レストランで例えると、Lambda関数はレストラン全体で、ハンドラー関数はお客さんが入ってきたときに最初に対応する人みたいな関係です。
AWSコンソールで「Lambda関数を作成」と言うときは前者、コードの中で `lambda_handler` を書いているときは後者を指している、という感覚で使い分けます。
AWSコンソールでLambda関数を作成してみる
ここからは実際にAWSコンソールで最小構成のLambda関数を作って動かしていきます。
CLIでもできますが、最初は画面を見ながらの方が「どこに何が設定されているか」が掴みやすいので、コンソールで進めます。
関数の作成画面でランタイムを選ぶ
Lambdaのコンソールトップにある「関数の作成」ボタンから始めます。
一から作成(Author from scratch)を選び、関数名・ランタイムを指定するだけで作成できます。
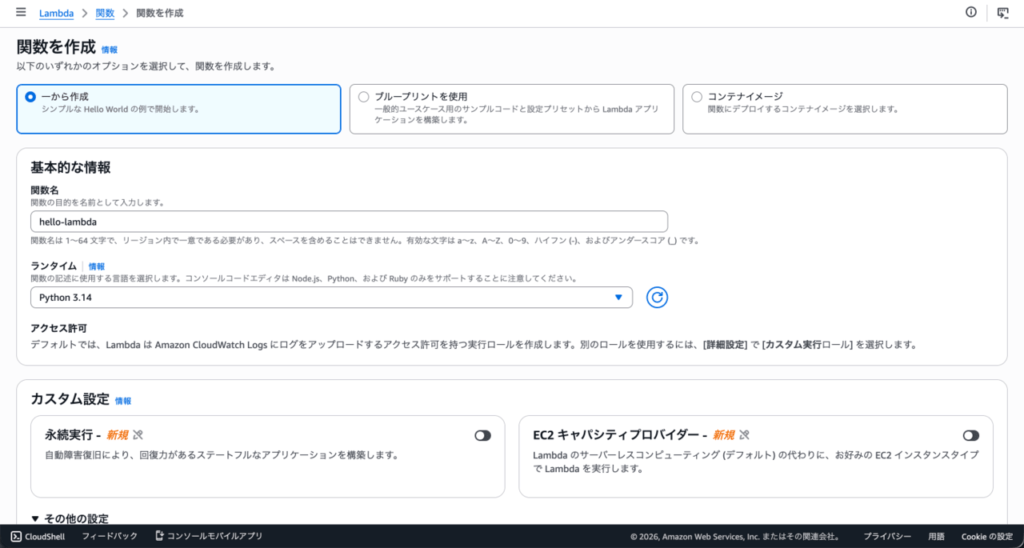
今回はPythonを選んでおきます。
ランタイムは後からでも変更できるので、ここはあまり悩まなくてOKです。
リージョンが意図したものになっているかだけ画面右上で確認しておきましょう。
Lambda関数はリージョンごとに独立して作成されるので、ここを間違えると後で「あれ、関数が見つからない…」となります。
デフォルトの実行ロールが自動で付く
「実行ロール」のセクションを開かずに作成ボタンを押しても問題ありません。
デフォルトで「基本的なLambdaアクセス権限で新しいロールを作成」が選ばれていて、CloudWatch Logsへの書き込み権限付きのIAMロールが自動で生成されます。
作成完了画面に遷移したらOKです。
ランタイムと実行ロールを確認する
念のため、生成された関数の中身を確認しておきましょう。
コード画面の下のほうにランタイムが、設定タブのアクセス権限セクションに実行ロールが表示されています。
Pythonランタイムが正しく選ばれていればここはOKです。
実行ロールも自動生成されたロールが紐付いていて、リンクをクリックするとIAMコンソールに飛んで、付与されているポリシー(CloudWatch Logsへの書き込み)を確認できます。
これで最小構成のLambda関数が手元にできました。次はテストイベントを使って実際に動かしてみます。
テストイベントを作成して実行する|Duration・Init Durationの読み方
関数ができたら、次はAWSコンソールに用意されているテストイベントを使って実際に動かしてみます。
本番ではS3やSQSなど別のサービスから渡されるイベントですが、開発段階では自分でJSONを書いて流し込めるので、最初の動作確認にはこれが一番手軽です。
テストイベントを保存する
関数の編集画面の上部にある「テスト」タブを開き、テストイベントを新規作成します。
テンプレートから「hello-world」のようなサンプルを選んでもいいし、自分で空のJSONでも問題ありません。
イベント名を付けて保存ボタンを押すと、こんな画面になります。
実行して結果を見る
保存したテストイベントを使って「テスト」ボタンを押すと、関数が起動して実行されます。
成功すると緑色のメッセージと一緒に、関数の戻り値(return された内容)が表示されます。デフォルトコードでは `{“statusCode”: 200, “body”: “Hello from Lambda!”}` がそのまま見えるはずです。
Duration・Init Duration・課金対象を読む
実行完了画面の「詳細」を開くと、実行にかかった時間の内訳が表示されます。
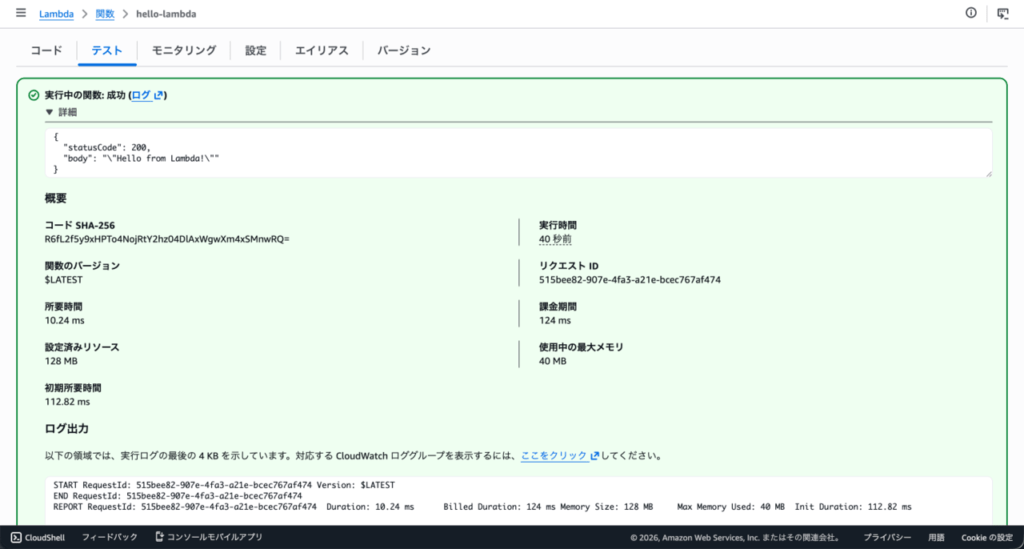
ここで見ておきたいのが3つの数値です。
| 項目 | 意味 |
| Duration | ハンドラー関数の実行時間。コードのパフォーマンスを反映する |
| Init Duration | 実行環境を立ち上げてランタイムを準備するまでの時間。コールドスタート時のみ表示される |
| Billed Duration | 課金対象になる時間。1ms単位で切り上げられる |
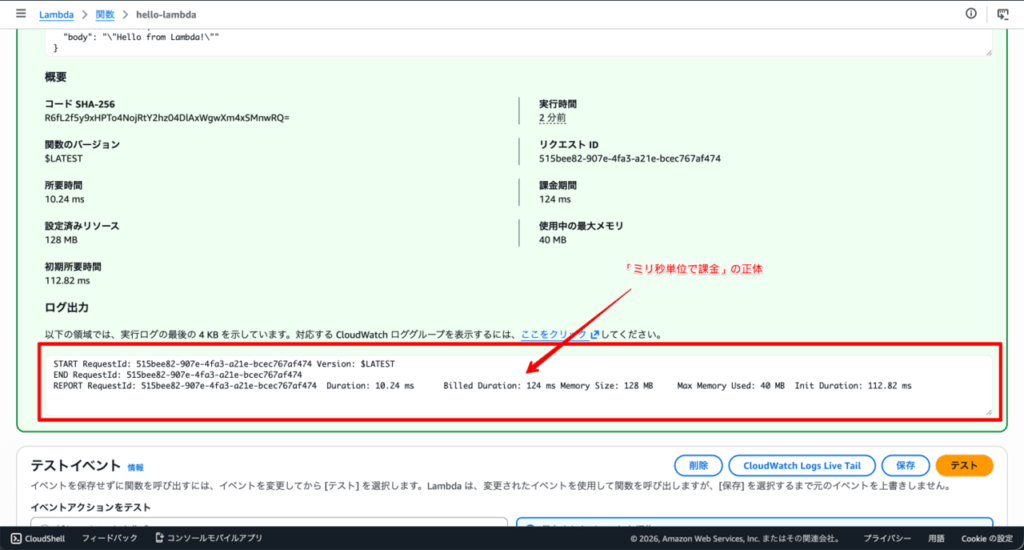
ここが実は面白くて、2回続けて実行するとInit Durationが消えます。
1回目はコールドスタートで実行環境のセットアップが必要だったのに対し、2回目はウォームスタートでその工程が省かれているからです。
さっき出てきた「ウォームスタート」が画面で確認できる瞬間でもあります。
これでLambda関数を動かすところまで体験できました。次は実行ログをCloudWatch Logsで覗いてみます。
CloudWatch Logsで実行ログを確認する|printを足してみる
Lambda関数を動かしたら、ログがどう残っているのかをCloudWatch Logsで確認してみます。
CloudWatchへ飛ぶ
実行完了画面の上部に「CloudWatch Logsを表示」のリンクがあるので、そこから関数のロググループに飛べます。
ログイベント一覧を開くと、こんな画面に切り替わります。
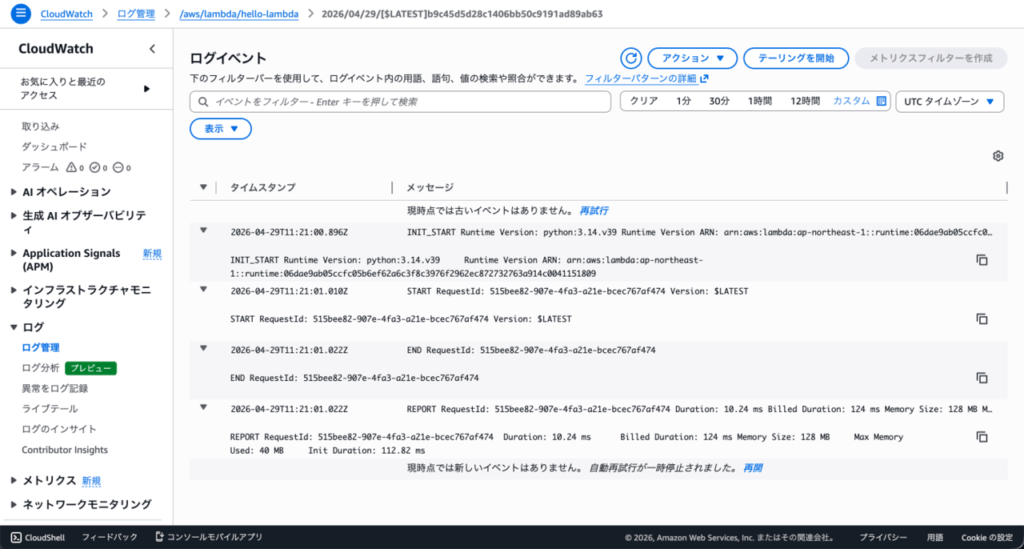
returnの中身がログに出ない理由
ログを覗くと、`INIT_START`、`START`、`END`、`REPORT` の行は並んでいるのに、デフォルトコードで return している `Hello from Lambda!` がどこにも見当たりません。
returnした値はCloudWatch Logsには出ないのがLambdaの仕様です。
ここは自分も最初に「あれ?」となったポイントで、以下のように役割が完全に分かれています。
| 出力先 | |
| return | 呼び出し元への返り値(同期実行ならコンソールの結果欄、API Gatewayなら HTTPレスポンス) |
| print / console.log / logger.info | CloudWatch Logs |
自販機で例えるなら、returnは取り出し口に出てくるジュース、printは裏の作業日誌みたいな感じで、見たい人が見たい場所で別々に取り出します。
printを追加して再Deployしてみる
ログにメッセージを残したいなら、ハンドラー関数の中に `print()` を書きます。例えばこんな感じです。
def lambda_handler(event, context):
print("これは CloudWatch に出るのですが")
print(f"受け取ったevent: {event}")
return {"statusCode": 200, "body": "Hello from Lambda!"}
ここで一つ注意点があって、コードを編集しただけではLambdaに反映されないので、画面右上の「Deploy」ボタンを忘れずに押します。
Deploy完了後にもう一度テストを実行すると、CloudWatch Logsにprintの内容が追加されます。
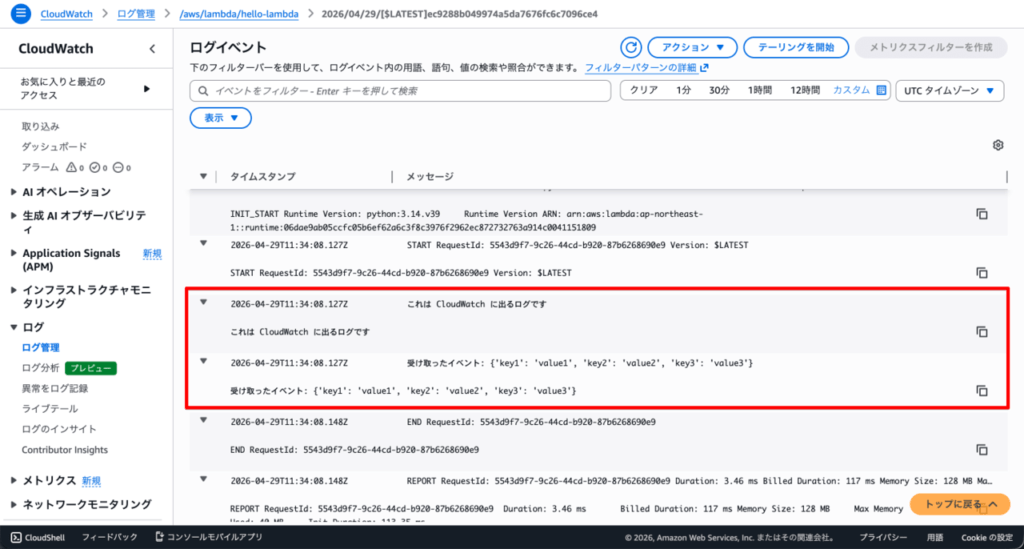
これで「returnは呼び出し元、printはCloudWatch」という分業が目で確認できました。
contextの中身を覗くなら vars(context)
ハンドラーの第2引数 `context` には、その実行に関するメタ情報が詰まっています。よく使うのはこのあたりです。
| 属性 | 内容 |
| `function_name` | 関数名 |
| `aws_request_id` | リクエストID。ログ追跡に便利 |
| `get_remaining_time_in_millis()` | タイムアウトまでの残り時間 |
| `memory_limit_in_mb` | 設定されているメモリ量 |
`print(context)` だけだとオブジェクトのアドレスしか出ないので、中身を一気に覗きたいときは `print(vars(context))` を使うと辞書化された属性がまとめて見られます。
実運用ではreturnの行き先がモデルで変わる|同期・非同期・ポーリング
ここまで触ってみて「Lambdaは呼び出されて、処理して、returnしたら呼び出し元に戻す」という流れがイメージできてきたと思います。
ただ、実はreturnの行き先はLambdaの呼び出しモデルによって変わるので、ここを整理しておかないと実運用で混乱します。
呼び出しモデルは大きく3つに分けられます。
| モデル | 呼び出し元の例 | returnの行き先 |
| 同期 | API Gateway、コンソールのテストボタン | 呼び出し元に直接返る |
| 非同期 | S3イベント、SNS | 基本どこにも送られない(Destinationsで送り先を指定可) |
| ポーリング | SQS、Kinesis、DynamoDB Streams | return値そのものは送られないが、return成功=処理OKの合図 |
同期モデル|returnがそのまま返る
API Gatewayで作ったWebAPIのように、呼び出し元がLambdaの結果を待っているケースが同期です。
Lambdaがreturnした内容がそのまま呼び出し元に返るので、HTTPレスポンスの中身としても使えます。
コンソールのテストボタンも同期実行で、結果欄にreturnの中身が表示されるのもこのモデルだからです。
非同期モデル|returnは呼び出し元には返らない
S3にファイルがアップロードされた、SNSに通知が来た、というイベントで起動するケースは非同期です。
呼び出し元はLambdaにイベントを投げたあとは結果を待たずに次に進むので、returnした内容は基本どこにも送られません。
「ログには記録されるけど、誰かに渡るわけではない」というイメージです。
どうしてもreturnの結果を別のサービス(別のLambdaやSQSなど)に流したい場合はDestinationsという機能で送り先を指定できます。
ポーリングモデル|returnは「処理OK」の合図になる
SQSと組み合わせて使うときに重要なのがポーリングモデルです。
LambdaがSQSキューを定期的に覗きに行ってメッセージを取り出し、ハンドラーに渡してくれます。
ここで面白いのが、returnの値そのものは特に使われないという点。代わりに、Lambdaが正常にreturnしたかどうかが「処理が完了したかどうか」の合図になります。
SQSはこれを受けて `DeleteMessage` を呼び出してメッセージをキューから消します。
前回のSQS記事で出てきた可視性タイムアウトとDeleteMessageの仕組みと、このLambdaの挙動が綺麗に噛み合うんですよね。
「処理が終わったらメッセージを消す」というSQSの作法を、Lambdaが代行してくれている形になります。
SQS連携の落とし穴|try/exceptの握りつぶしが「成功」と判定される
ポーリングモデルの「return成功=処理OK」という合図、シンプルでいいんですが、ここに地味な落とし穴があります。
LambdaはreturnかExceptionかの二択でしか成否を見ていないので、return値の中身は一切判定に関わりません。
つまり、こういうコードを書くとSQS連携で痛い目を見ます。
def lambda_handler(event, context):
try:
do_something_risky(event)
except Exception as e:
print(f"エラーが起きた: {e}")
return {"statusCode": 500, "body": "failed"} # ← ここがマズい
例外をtry/exceptで握りつぶしてreturnすると、Lambdaにとっては「正常終了」なので、SQSは「処理が完了した」と判断してメッセージを削除してしまいます。
実際は処理が失敗しているのに、リトライもされず、メッセージが闇に消えます。
失敗を伝えたいときはraiseで例外を再送出する
Lambdaに「これは失敗だよ」と伝えるには、例外をそのまま外に投げ返す必要があります。
def lambda_handler(event, context):
try:
do_something_risky(event)
except Exception as e:
print(f"エラーが起きた: {e}")
raise # ← 例外を再送出
こうしておけば、LambdaがExceptionを受け取って失敗扱いし、SQSは可視性タイムアウト後にメッセージを再度配信してくれます。
リトライ回数を超えればデッドレターキュー(DLQ)に流す、という前回SQS記事で触れた流れにもそのまま乗ります。
バッチ処理ならPartial Batch Responseという選択肢もあるらしい
これは自分もまだ試してはいないのですが、SQSとLambdaの連携では、複数のメッセージをまとめて1回のLambda呼び出しで処理することもできるみたいです。
このときバッチの中の一部だけ失敗したケースで「全部失敗扱いにする」と無駄が多いので、AWSにはPartial Batch Responseという仕組みが用意されているみたいです。
ハンドラーの戻り値で「失敗したメッセージのID」を指定すると、そのメッセージだけが再配信されるとのことなので、最初のうちは「raiseで全件リトライ」で十分そうですが、バッチ処理に踏み込むタイミングで思い出すと役立ちそうです。
Lambdaを腹落ちさせるために押さえた3つのポイントと、次に試したいこと
ここまでLambdaを概念から最小構成まで触ってきましたが、自分の中で「腹落ちした」と感じたのは、結局は次の3つのポイントに行き着きます。
- プロセスの寿命:Lambdaは常駐ではなく、イベントごとに起動・終了する。状態をプロセス内に持つ発想を捨てる
- 実行ロール:呼び出し元の権限ではなく、Lambda関数自身がAWSのリソースを触るときに使う権限。CloudWatch Logsへの出力もこれで成り立つ
- return値は無関係:SQSなどポーリング型では、return値の中身ではなく「正常終了か例外か」だけが処理の成否判定に使われる
サーバープログラムの感覚をいったん脇に置いて、この3つを軸に組み立て直すと、Lambdaの動きや設計判断がスッと噛み合うようになります。
次はSQS → Lambda → メール送信を組んでみる
最小構成で動かすところまでは見えたので、次はSQS → Lambda → メール送信(SES)という、もう少し実用に近いパイプラインを組んでみたいと思っています。
- SQSにメッセージを投げると
- Lambdaがそれを拾って
- SESでメールが飛ぶ
という流れで、SNS・SQS・Lambdaの学習がやっと一本の線で繋がる予定です。
次の記事ではそのあたりを書こうと思うので、よかったら一緒に試してみてください。