記事の目次
Amazon検索結果一覧から商品詳細ページのURLを抜き出したかった
普段はPHPでスクレイピングしてるんですが、やはり計算やスクレイピングするだけなどWeb表示しない場合はpythonの方が断然強いということで、今回はpythonでAmazonページをスクレイピングしようと思いました。
僕自身がセドリとかしてるわけじゃないんですが、クラウドワークスなどの募集でしょっちゅうJANコードやASINコードの取得案件があるので、この辺のスクレイピング用プログラムを作っとけば、よりコスパよく案件を受けられると思ったからです。
ではさっそくと、自分のMacBookProにpyenvで開発環境を用意しスクレイピング開始。
pythonのスクレイピング用ライブラリのBeautiful Soupを使ってみた
僕は普段からpythonを使っているわけではないので、どうゆうライブラリがあるかを軽く調べたら出るわ出るわ!
そこで今回はpythonでスクレイピングするなら定番ライブラリっぽい`Beautiful Soup`を使おうと思いました。
この辺は腐るほど情報が溢れているので簡単にソース取得までできたので、後はソースを解析しながら自分の欲しい商品個別ページのURLを絞り込もうと思った矢先!!!
HTMLパースまでは取得できてるのに絞り込みだと取得できない
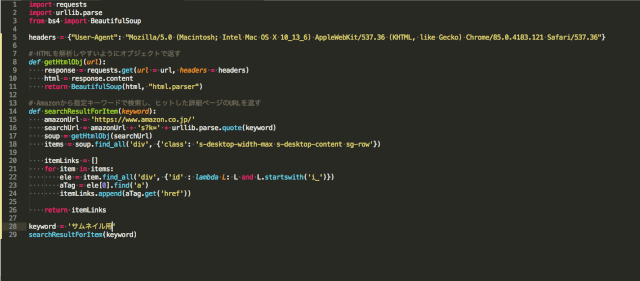
まずAmazonの検索結果ページの中で、検索にヒットした商品一覧が表示されているHTML構造は下記部分になります。
<div class='sg-col-20-of-24 sg-col-28-of-32 sg-col-16-of-20 sg-col sg-col-32-of-36 sg-col-8-of-12 sg-col-12-of-16 sg-col-24-of-28'>
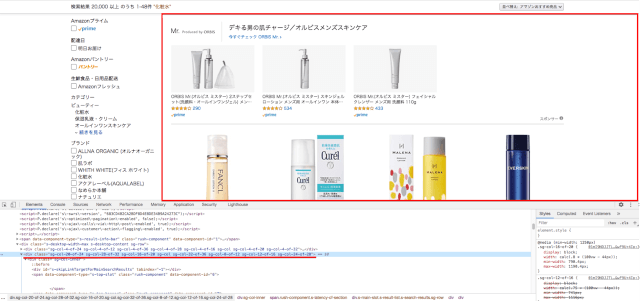
これはBeautiful SoupでHTMLパースした段階では確認できます。
def getHtmlObj(url): response = requests.get(url = url, headers = headers) html = response.content soup = BeautifulSoup(html, "html.parser") print(soup)
普通ここまで取得できていれば、あとは下記コードで絞り込みされるはずです。
soup.find_all('div', class_="sg-col-20-of-24 sg-col-28-of-32 sg-col-16-of-20 sg-col sg-col-32-of-36 sg-col-8-of-12 sg-col-12-of-16 sg-col-24-of-28")
できな〜〜〜〜い_| ̄|○ il||li
何度やろうが、下記コードに書き直してみてもダメ!
soup.find_all('div', {'class': 'sg-col-20-of-24 sg-col-28-of-32 sg-col-16-of-20 sg-col sg-col-32-of-36 sg-col-8-of-12 sg-col-12-of-16 sg-col-24-of-28'})
`Beautiful Soup`の上記書き方で複数classも絞り込みできるって書いてるのに〜。
こうゆうエラーでもなく中のコードも見えない時が完全に詰む(´;ω;`)
pythonでのスクレイピングにお手上げです
もうpython、Beautiful Soup初心者とか関係なくお手上げです。
今どきスクレイピングなんて専用ライブラリも出てるくらいだから簡単だと思ったのに。
取り敢えず自分ではやれることも見つからないのでseleniumに切り替えて行こうと思います。
どなたか心優しい方、こちら からアドバイスをお願いします( ˃̣̣̥人˂̣̣̥ )